API Integration Platform Comparison: Top Tools for 2026

/TABLE OF CONTENTS
/ARTICLE
/ARTICLE
[1]TLDR
- REST + OpenAPI is the right default for external-facing APIs but a poor long-term choice for internal service communication, schema drift is a runtime problem, not a compile-time one.
- gRPC and Buf Connect give you strong typed contracts across languages but require maintaining
.protofiles manually, the drift risk is lower than REST but the maintenance overhead is real and compounds with service count. - tRPC offers the cleanest developer experience for TypeScript-only stacks with zero schema files, but is a non-starter the moment a non-TypeScript service enters the picture.
- Graftcode eliminates both the schema file and the HTTP boilerplate across 20 languages, typed interfaces install via package manager, and GraftConfig switches between in-memory local dev and remote production without a code change.
- The real evaluation criteria most tool comparisons miss is integration maintenance overhead, the 30–40% of backend engineering time lost to HTTP clients, DTO drift, and SDK versioning that compounds silently as your service count grows.
Backend teams burn more engineering time on integration plumbing than anyone budgets for. Writing HTTP clients, maintaining DTO schemas, keeping SDK versions in sync across services, none of it ships product. And as the service count grows, the overhead compounds. Each new service is another contract to write, another schema to keep current, another thing that breaks silently when the provider changes something.
Graftcode takes a different approach to this. Instead of a protocol or a schema file, it generates a strongly-typed interface inside the calling service, installed via package manager, works across 20 languages, runs in-memory locally and remote in production without a code change. This blog looks at how that holds up against the tools most backend teams are already looking at: REST + OpenAPI, gRPC, Buf Connect, and tRPC. What each one does, where it fits, and where it falls short.
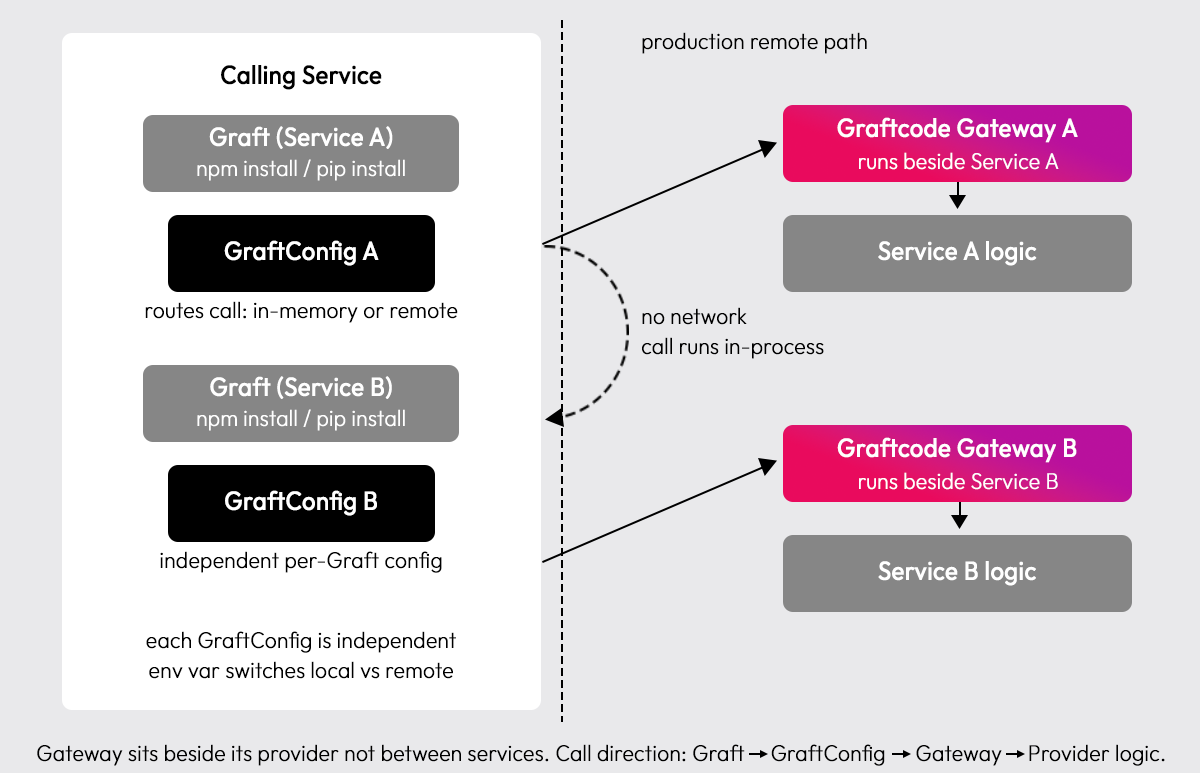
Graftcode's architecture differs from a traditional API gateway setup. The Graftcode Gateway runs beside the provider service, not between the caller and provider. Routing logic lives in GraftConfig inside the calling service, which means switching from local in-memory calls to remote production calls is an environment variable change, not an infrastructure change.
[2]What API Integration Platforms Are and Why the Choice Is Harder Than It Looks
Every production backend eventually hits the same wall. Services need to talk to each other, reliably, with predictable contracts, across different languages and runtimes. The first instinct is usually to reach for REST. You write an HTTP client, define a response schema, ship it, and move on. Then the provider service changes a field name. Or adds pagination. Or the DTO you wrote six months ago quietly drifts from what the API actually returns. By the time you have five or six services, a meaningful chunk of your engineering time is just keeping these integrations from breaking.
API integration platforms exist to solve this. The category is broad, it includes everything from SaaS automation tools like MuleSoft to low-level RPC frameworks like gRPC. What they share is a common goal: reduce the overhead of wiring services together so teams can focus on product logic instead of plumbing.
This comparison focuses on a specific slice of that category, tools backend engineers reach for when building or migrating to microservices. Not SaaS connectors, not workflow automation. The question here is: when two of your own services need to communicate, what layer do you put between them, and what does that choice cost you over time?
The five tools covered, Graftcode, gRPC, Buf Connect, tRPC, and REST + OpenAPI, each answer that question differently. Some require you to maintain a separate schema file. Some lock you into a single runtime. Some hand the problem back to the infrastructure layer. Understanding those tradeoffs upfront is what makes the rest of this comparison useful.
[3]What to Look for When Evaluating API Integration Platforms
Choosing an integration layer is not just a protocol decision, it's a maintenance decision. The tool you pick in year one is the one your team is debugging, versioning, and working around in year three. Before comparing specific tools, it helps to have a consistent set of criteria to evaluate them against.
- Type safety and contract enforcement: does the tool catch breaking changes at compile time or in production? A field rename, a changed response shape, a new required parameter, without compile-time enforcement, these become runtime errors.
- Schema and contract maintenance overhead: gRPC requires
.protofiles, OpenAPI requires a spec file, both need to stay in sync with the actual service implementation manually. That sync work is easy to underestimate until you're three services deep and contracts are already drifting. - Language and runtime support: determines whether the tool works across your whole stack or only part of it. A TypeScript-only tool is a real constraint for teams running Python inference services alongside Node.js APIs.
- Local development experience: if running two services locally requires spinning up a gateway, generating stubs, or mocking HTTP calls, the feedback loop slows down. The best tools let engineers run everything in-process without infrastructure overhead.
- Migration friendliness: does the tool support gradual service extraction or does it require a full cutover? For teams mid-migration from a monolith, this is often the deciding factor.
- Runtime performance: CPU and latency per inter-service call matters less for low-frequency requests and significantly more for high-throughput workloads like inference pipelines or agent orchestration layers.
With those criteria in place, here is how the five platforms actually compare.
[4]Best Five API Integration Platforms Comparison in 2026
Before getting into the per-tool breakdown, here's how all five compare across the criteria that matter most. If your team has a clear constraint, language lock-in, schema overhead, local dev friction, this table is the fastest way to filter.
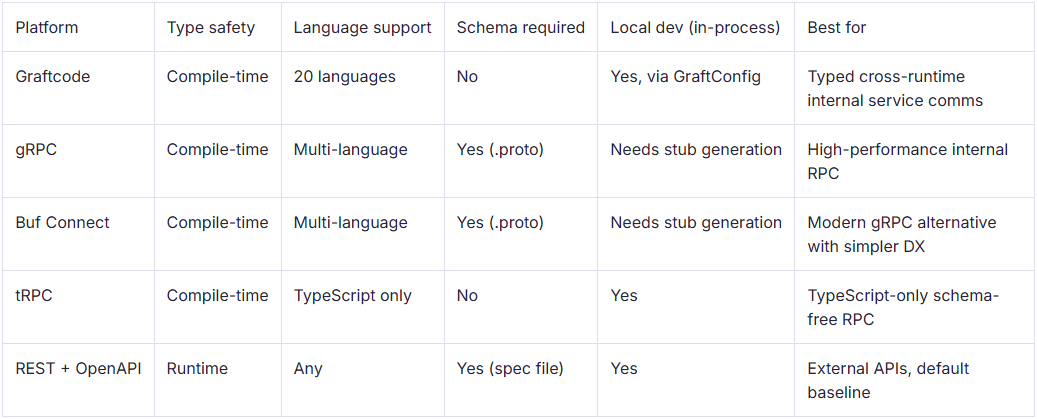
The table above captures features. This matrix shows where each tool creates ongoing engineering overhead. Schema maintenance and language coverage are the two axes where the tools diverge most sharply, and where the wrong choice compounds fastest as service count grows.
A few things worth calling out before the per-tool breakdown:
- REST + OpenAPI's type safety is marked partial because the spec file and the actual implementation can drift, the type safety is only as good as the discipline around keeping them in sync.
- gRPC and Buf Connect both require stub generation before local dev works cleanly, which adds friction to the inner loop.
- tRPC's in-process local dev works well, but the TypeScript-only constraint means it doesn't appear in the running for multi-language stacks at all.
- Graftcode's local dev story, where GraftConfig switches a call from remote to in-memory without a code change, is the most friction-free of the five for teams running mixed-language services.
Those distinctions matter more in practice than a table cell can show. The breakdown below gets into how each tool handles the real integration work, contracts, local dev, maintenance overhead, and where things start to fall apart at scale.
Graftcode: Typed Cross-Runtime Service Communication Without the Plumbing
Graftcode is a cross-runtime communication layer that lets services call each other's public methods directly, no REST endpoints, no proto files, no message queue contracts.
A Graft is a strongly-typed interface generated inside the calling service via package manager. GraftConfig controls whether the call runs in-memory locally or remote in production, same code, no changes. The Graftcode Gateway runs alongside the provider service and exposes its public methods to callers.
Key features:
- Strongly-typed interfaces generated via
npm install,pip install, ormaven add - Supports 20 programming languages and 10 package managers
- GraftConfig switches between in-memory and remote via environment variable, no code change
- Interface changes surface as package updates, teams control when to apply them
- 70% faster than web services, one-eighth the CPU of equivalent gRPC or REST calls
The difference isn't just fewer lines of code. The REST version has no compile-time visibility into the provider's interface, a field rename in the response is a KeyError in production. The Graftcode version surfaces that change as a package update before deployment.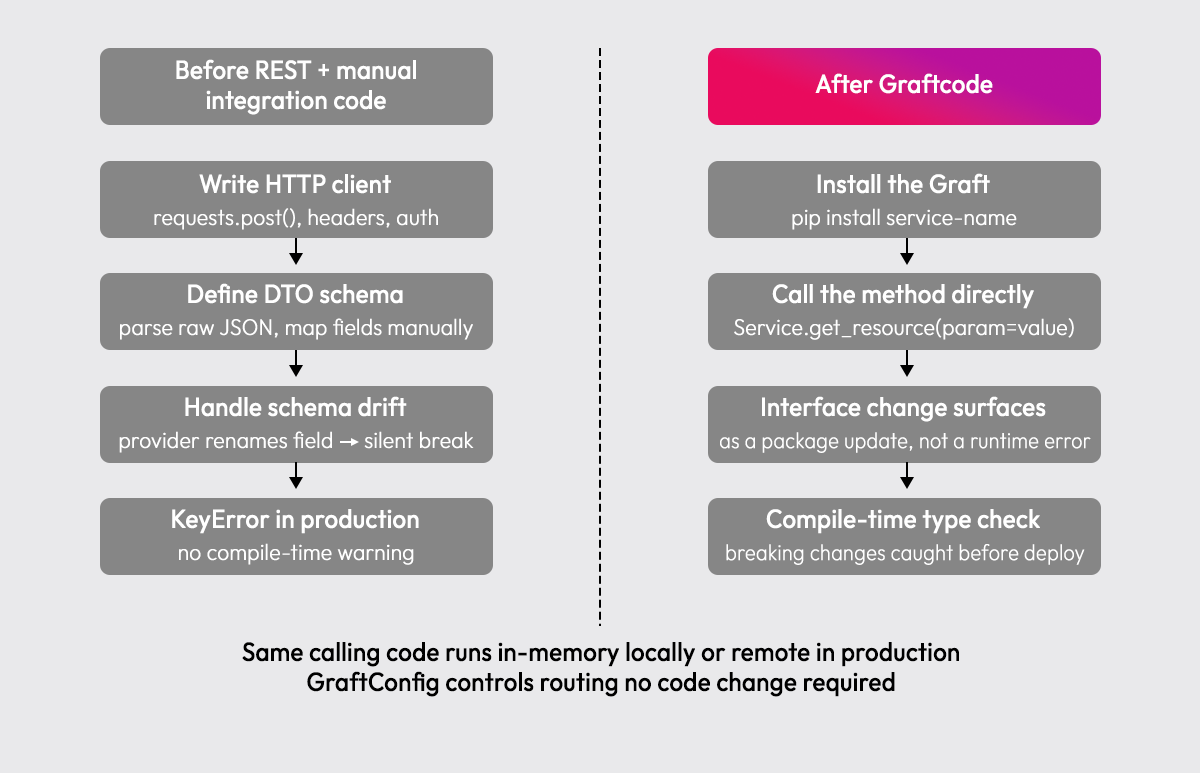
Where it fits:
- Multi-language microservices stacks with high integration overhead
- Teams mid-migration from monolith to microservices
- High-throughput internal service communication (inference pipelines, agent orchestration)
- AI and agentic systems requiring typed, reliable inter-service calls
Where it doesn't:
- External-facing public APIs for third-party developers
- Teams needing full API gateway features, rate limiting, auth plugins, developer portals
Verdict: The strongest option for internal typed service communication across languages, with the lowest local dev friction of the five.
gRPC: High-Performance Typed RPC With Proto File Overhead
gRPC is an open-source RPC framework from Google that uses Protocol Buffers as its interface definition language and HTTP/2 as its transport layer.
Services define their interfaces in .proto files, from which gRPC generates client and server stubs in the target language. The generated stubs are strongly typed and the contract is explicit, but the .proto file is a separate artifact that lives outside your service code and needs to stay manually in sync with the actual implementation.
Key features:
- Strongly-typed interfaces via Protocol Buffers (
.protofiles) - HTTP/2 transport, supports streaming, multiplexing, and low-latency calls
- Multi-language code generation from a single
.protodefinition - Built-in support for bidirectional streaming
- Wide ecosystem support, Kubernetes, Envoy, service meshes
Where it fits:
- High-throughput internal service communication where performance is the priority
- Teams already invested in a Protobuf-based workflow
- Polyglot stacks where a shared
.protocontract is manageable - Systems requiring bidirectional or server-side streaming
Where it doesn't:
- Teams without tooling discipline around
.protofile maintenance, contract drift is a real risk - Local development without stub generation setup adds friction to the inner loop
- Browser clients, gRPC-Web adds complexity and is not a clean solution
Verdict: Strong performance and type safety, but the proto maintenance overhead is a real ongoing cost that compounds as the number of services grows.
Buf Connect: Modern Proto-Based RPC With a Simpler Developer Experience
Buf Connect is a modern RPC framework built on Protocol Buffers, developed by Buf Technologies. It is gRPC-compatible but designed to work cleanly over HTTP/1.1 and HTTP/2 without the infrastructure complexity that raw gRPC brings.
Like gRPC, Buf Connect uses .proto files for interface definitions and generates typed client and server code. The difference is in the tooling layer, Buf's CLI handles linting, breaking change detection, and schema registry management, which addresses some of the .proto drift problem that gRPC leaves to team discipline. It also works natively in browsers without the gRPC-Web workaround.
Key features:
- gRPC-compatible, works with existing gRPC infrastructure
- Runs over HTTP/1.1 and HTTP/2 natively
- Buf CLI adds linting, breaking change detection, and a schema registry (Buf Schema Registry)
- Browser-native, no gRPC-Web layer needed
- Supports streaming, same as gRPC
Where it fits:
- Teams evaluating gRPC but wanting better tooling around proto maintenance
- Systems that need browser compatibility alongside backend service communication
- Teams already using Protobuf who want breaking change detection built into CI
- Greenfield microservices projects where the Buf ecosystem is adopted from the start
Where it doesn't:
- Still requires
.protofiles, the schema maintenance problem is reduced, not eliminated - Smaller ecosystem than gRPC, fewer ready-made integrations and community resources
- Teams without an existing Protobuf workflow face the same onboarding curve as gRPC
Verdict: A meaningful improvement over raw gRPC on the tooling side, but the fundamental dependency on schema files remains, teams still own the contract maintenance problem.
tRPC: Schema-Free Type Safety Locked to TypeScript
tRPC is an RPC framework for TypeScript that provides end-to-end type safety between services without any schema files or code generation step.
Instead of a .proto file or an OpenAPI spec, tRPC infers types directly from the server-side function definitions. The calling service gets full TypeScript type safety on every procedure call, if the server changes a return type or parameter, the client catches it at compile time. The tradeoff is that this inference only works when both sides are TypeScript, making it a non-starter for polyglot stacks.
Key features:
- End-to-end type safety with zero schema files or code generation
- Types inferred directly from server router definitions
- Works over HTTP or WebSockets
- Lightweight, minimal runtime overhead
- Strong integration with Next.js, React, and the broader TypeScript ecosystem
Where it fits:
- TypeScript monorepos where the calling and provider services share a codebase
- Full-stack TypeScript teams building internal service communication
- Teams that want Graftcode-like type safety without adopting a new runtime layer
- Next.js backends communicating with internal TypeScript services
Where it doesn't:
- Any stack with non-TypeScript services, Python, Java, Go, Rust, is completely out of scope
- Teams that need cross-language support will hit a hard wall immediately
- Not designed for high-throughput internal RPC at the infrastructure level
Verdict: The cleanest developer experience for TypeScript-only stacks, but the runtime lock-in makes it irrelevant the moment a non-TypeScript service enters the picture.
REST + OpenAPI: The Default Baseline Most Teams Are Already On
REST over HTTP is the default starting point for inter-service communication, not because it's the best option, but because it requires no new tooling, works across every language, and every developer already knows it.
OpenAPI adds a spec layer on top, a YAML or JSON file that describes endpoints, request shapes, and response schemas. Code generators like openapi-generator can produce typed clients from that spec, which gives partial type safety. The problem is that the spec is a separate artifact. It doesn't automatically stay in sync with the implementation, and in practice most teams let it drift. A field gets renamed, an endpoint gets added, and the spec update happens later, or not at all. That drift is a runtime problem, not a compile-time one.
Key features:
- Works over standard HTTP, no new protocols or tooling required
- OpenAPI spec enables documentation, client generation, and basic contract definition
- Language-agnostic, every runtime has HTTP client libraries
- Large ecosystem, testing tools, mocking frameworks, API gateways all speak REST
- Human-readable, endpoints and payloads are inspectable without special tooling
Where it fits:
- External-facing APIs for third-party developers or partners
- Public APIs where discoverability and documentation matter
- Teams with mixed technical backgrounds where REST's simplicity reduces onboarding friction
- Integrating with third-party services that only expose REST endpoints
Where it doesn't:
- Internal high-throughput service communication, HTTP overhead adds up at scale
- Teams where schema discipline is inconsistent, OpenAPI drift is a persistent maintenance problem
- Polyglot microservices stacks where typed contracts across services are a priority
Verdict: The right default for external APIs, but a poor long-term choice for internal service communication in teams that care about type safety and integration maintenance overhead.
[5]Choosing the Right Platform for Your Team and Stack
Tool comparisons are only useful if they map to real decisions. The right integration layer depends on your stack, your team size, and how much contract maintenance overhead you can absorb long-term. The scenarios below cover the most common situations backend teams run into.
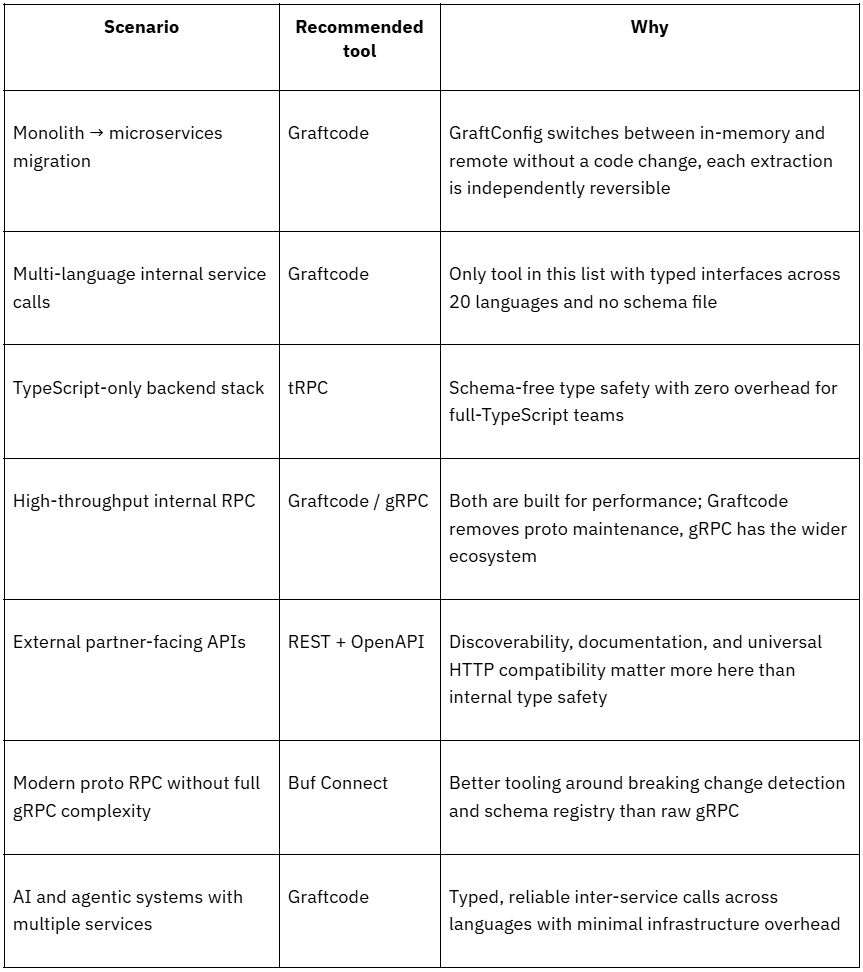
A few patterns worth noting across these scenarios:
- Schema-dependent tools (gRPC, Buf Connect, REST + OpenAPI) work well when contract maintenance is owned by a dedicated platform team. Without that ownership, drift is inevitable.
- tRPC is the right call for TypeScript shops, but the decision is essentially made for you, if any service in the system isn't TypeScript, it's off the table.
- Graftcode covers the widest range of the scenarios above, specifically because it solves the schema maintenance problem without trading away type safety or language support.
The scenario that comes up most often and gets the least attention in tool comparisons is the mid-migration monolith. Teams in that state need something that works incrementally, where each service extraction doesn't require a full protocol cutover and can be reversed if something goes wrong. GraftConfig's environment variable switching is the most practical answer to that specific problem in this list.
[6]The Hidden Cost Most API Integration Comparisons Ignore
Feature tables are easy to produce. What they don't show is the engineering time that accumulates quietly in the background, the hours spent writing HTTP clients, updating DTO schemas, regenerating stubs after a proto change, debugging a field mismatch that only showed up in production. This is the API plumbing tax, and it's the real cost of the integration layer you choose.
Integration plumbing doesn't show up as a sprint ticket. It shows up as the reason tickets take longer than estimated. The breakdown above reflects what that 30–40% actually consists of across a typical backend team running five or more services, and which parts disappear when the integration layer enforces typed contracts automatically.

For most teams, that tax runs between 30–40% of backend engineering time. It doesn't show up as a line item in sprint planning. It shows up as the reason a feature that should have taken two weeks took four, because three services needed updated clients, two DTOs needed reconciling, and someone spent a day tracking down why the response shape changed without the spec being updated.
The tools in this comparison handle that tax differently:
- REST + OpenAPI doesn't reduce it, it just makes it more structured. The spec file is still a manual artifact.
- gRPC and Buf Connect reduce drift risk through code generation, but the
.protofile is still something your team owns and maintains. - tRPC eliminates the schema file entirely, but only for teams where every service is TypeScript.
- Graftcode eliminates the schema file and the HTTP boilerplate across 20 languages, interface changes surface as package updates, and teams control when to apply them.
The integration layer isn't just a technical decision, it's an engineering time decision. A tool that looks lightweight in a feature comparison can quietly absorb weeks of engineering capacity per quarter once the service count grows past five or six. That's the number worth optimizing for, and it's the one most tool evaluations don't surface.
Picking the Right Integration Layer for Your Microservices Stack
REST + OpenAPI remains the right call for external APIs. gRPC and Buf Connect work well for teams with strong proto discipline. tRPC removes a real class of problems for TypeScript-only shops. Each tool has a clear fit, and an equally clear set of constraints that make it the wrong choice outside that fit.
The decision gets harder for teams building internal service communication across languages, mid-migration from a monolith, or standing up AI systems where multiple services need typed, reliable communication at speed. That's where integration overhead compounds fastest, and where the choice of tool has the most impact on engineering time.
For teams in that space, Graftcode is worth a close look. The documentation covers setup end-to-end, from installing your first Graft to configuring remote deployments. The introduction page is a good place to start if you want to understand the architecture before touching any code.
[7]FAQ
Q1. How is Graftcode different from gRPC for internal microservices communication?
gRPC requires maintaining .proto files as a separate contract artifact, any interface change means updating the proto, regenerating stubs, and pushing that update across every calling service manually. Graftcode generates the typed interface directly from the provider's code and surfaces changes as package updates. No proto file, no manual stub regeneration, and the same calling code runs in-memory locally or remote in production via an environment variable change.
Q2. Can Graftcode be used during a monolith to microservices migration?
Yes, this is one of the strongest use cases. When a service is extracted from the monolith, the remaining codebase installs a Graft for that service and GraftConfig controls whether calls run in-process or remote. Switching between the two is an environment variable change, not a code change. Each extraction is independently reversible, which means teams can migrate incrementally without committing to a full cutover.
Q3. What is the difference between an API gateway and an API integration platform?
An API gateway, Kong, AWS API Gateway, Apigee, handles traffic management for external-facing APIs: routing, rate limiting, auth, and analytics. An API integration platform focuses on how services communicate internally, typed contracts, schema management, and reducing integration maintenance overhead. The two solve different problems and are not interchangeable.
Q4. When should a team use REST over a typed RPC framework like gRPC or Graftcode?
REST + OpenAPI is the right choice for external-facing APIs where discoverability, documentation, and broad client compatibility matter. For internal service-to-service communication in a microservices architecture, typed RPC frameworks reduce contract drift and catch breaking changes at compile time, something REST leaves to discipline and runtime debugging.
Q5. What is API integration overhead and why does it slow down engineering teams?
API integration overhead is the engineering time spent on plumbing work that doesn't ship product, writing HTTP clients, maintaining DTO schemas, keeping SDK versions in sync, and debugging contract drift between services. For most backend teams this runs between 30–40% of engineering capacity and compounds as service count grows. Choosing an integration layer that enforces typed contracts and reduces manual schema maintenance directly reduces this overhead.
/WRITTEN BY