gRPC vs REST: A Developer's Decision Guide for 2026

/TABLE OF CONTENTS
/ARTICLE
/ARTICLE
[1]TL;DR
- REST runs over HTTP/1.1 with JSON payloads and no enforced schema, the right default for external-facing APIs, browser clients, and interfaces that are still evolving.
- gRPC runs over HTTP/2 with Protobuf serialization and a required
.protocontract, the right fit for high-throughput internal services, polyglot systems, and latency-sensitive workloads like ML inference and agent orchestration. - The core technical tradeoff is performance and contract strictness vs. universality and ease of onboarding. Protobuf payloads run 3–10x smaller than equivalent JSON, and gRPC benchmarks consistently show lower p99 latency under high call volumes, but REST requires zero client setup and works natively in every browser.
- Neither protocol eliminates the integration maintenance work that accumulates as services grow. Writing HTTP clients, keeping DTO schemas in sync, and managing stub regeneration can consume 30–40% of backend engineering time, and that cost compounds with every service added to the system.
- Graftcode addresses that integration layer directly, strongly-typed interfaces installed via package manager, compile-time contract enforcement, and in-memory to remote routing via configuration. In the Performance Lab's large-payload test on HTTP/2, Graftcode completed in 22ms against gRPC's 53ms and REST's 1,245ms, 98.2% faster than REST, with one-eighth the CPU overhead.
Every distributed system needs a way for services to talk to each other. For most teams, that decision defaults to REST, it's familiar, works over plain HTTP, and any client can call it without special tooling. But as systems grow into multi-service architectures, and especially as AI inference pipelines and agent orchestration layers become common, the tradeoffs of that default choice start to surface.
gRPC has been the answer for many high-performance internal systems. It's faster, stricter, and better suited to high-throughput communication between services you control. But it comes with its own costs, a steeper learning curve, mandatory tooling, and a .proto maintenance cycle that compounds as the system grows.
This guide is a decision tool. It breaks down both protocols technically, maps them to the scenarios where each performs well, and covers what neither of them fully solves on their own.
[2]What REST and gRPC Are and What Problems They Solve
API communication protocols are easy to overlook when a system is small. They become impossible to ignore once you have ten services, three languages, and latency SLAs to hit.
REST: HTTP semantics with no enforced contract
REST is built on HTTP/1.1. Services expose resources at URLs, callers interact using standard HTTP verbs, and data moves as JSON. A typical call:
response = await client.post("http://inference-service/api/v1/inference",json={"model": "llama-3", "prompt": prompt, "max_tokens": 512})response.raise_for_status() # 4xx/5xx -- you get a status code, nothing morereturn response.json()
Any HTTP client works, no generated code, no special tooling. That universality is REST's core strength.
The weakness is contract enforcement. Nothing stops a provider from renaming max\_tokens to max\_new\_tokens, the calling service finds out at runtime as a silent null or a KeyError. OpenAPI specs help document the interface, but keeping client and server in sync is still a manual process.
- Transport: HTTP/1.1
- Payload: JSON, human-readable, easy to debug
- Schema: optional, enforced only if you add OpenAPI or similar
- Error handling: HTTP status codes, interpreted by the client, nothing enforced
- Client setup: zero, any HTTP client works
gRPC: contract-first RPC over HTTP/2
gRPC starts with a .proto file, the single source of truth for the service interface. protoc generates typed stubs from it. The calling service uses those stubs directly:
channel = grpc.insecure_channel("inference-service:50051",options=[("grpc.keepalive_time_ms", 10000)])stub = InferenceServiceStub(channel)try:response = stub.RunInference(InferenceRequest(model="llama-3", prompt=prompt, max_tokens=512),timeout=30.0)except grpc.RpcError as e:if e.code() == grpc.StatusCode.UNAVAILABLE:print("Service unavailable -- retry with backoff")elif e.code() == grpc.StatusCode.DEADLINE_EXCEEDED:print("Deadline exceeded")raise
If the provider renames a field in the .proto, the generated stub changes and the calling code fails to compile, before it reaches production.
One thing worth noting on error handling: gRPC uses its own status code system (UNAVAILABLE, DEADLINE\_EXCEEDED, NOT\_FOUND, INTERNAL), entirely separate from HTTP status codes. Code that handles REST errors with response.status\_code == 503 needs a full rewrite when migrating to gRPC. The two models don't map cleanly onto each other.
- Transport: HTTP/2, multiplexing, persistent connections, header compression
- Payload: Protobuf binary, typically 3–10x smaller than equivalent JSON
- Schema: required, the
.protois the enforced contract - Error handling: typed gRPC status codes, richer than HTTP but a separate system to learn
- Client setup:
protoc, generated stubs, regeneration step on every interface change
The setup cost is real. For internal services where you control both ends, it pays off quickly. For a public API with browser or third-party consumers, that overhead lands on every caller.
How REST and gRPC Differ at a Technical Level
Choosing between REST and gRPC isn't just a syntax preference, the two protocols make fundamentally different tradeoffs at the transport, serialization, and contract layers. Here's how they compare:
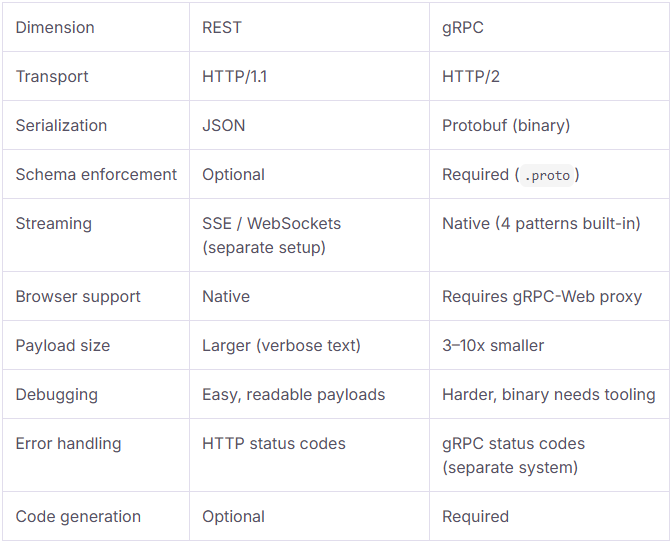
Transport: HTTP/1.1 vs HTTP/2
HTTP/2 gives gRPC three things REST on HTTP/1.1 doesn't have: multiplexing (multiple in-flight requests over a single connection), header compression, and persistent connections. In practice, this means fewer TCP handshakes, lower per-request overhead, and better behaviour under load. For an inference service handling hundreds of concurrent requests, that gap is measurable.
What actually runs when a method is called
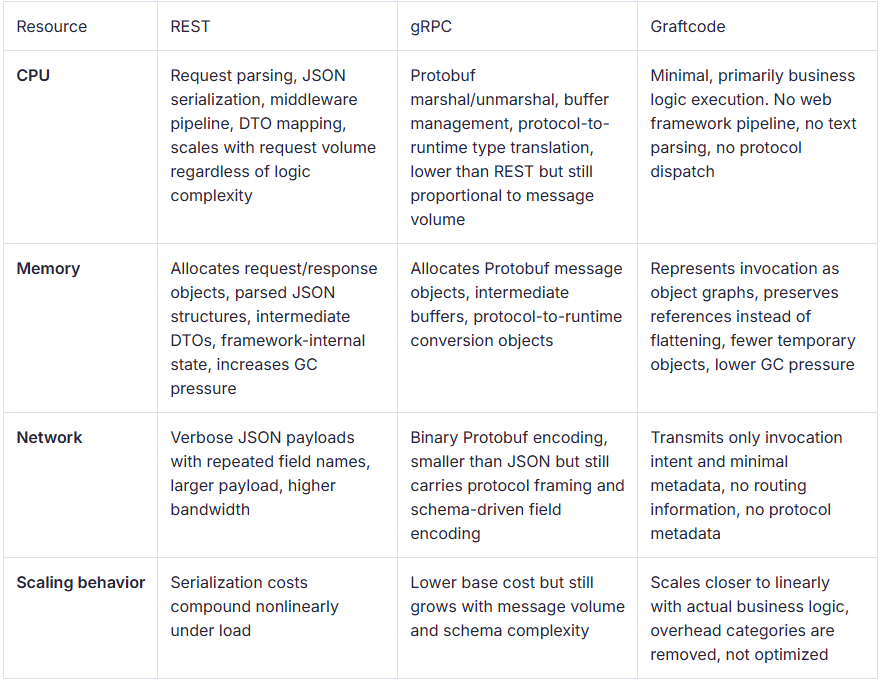
The table above compares protocol features. What it doesn't show is the execution pipeline each protocol runs through before business logic ever fires:
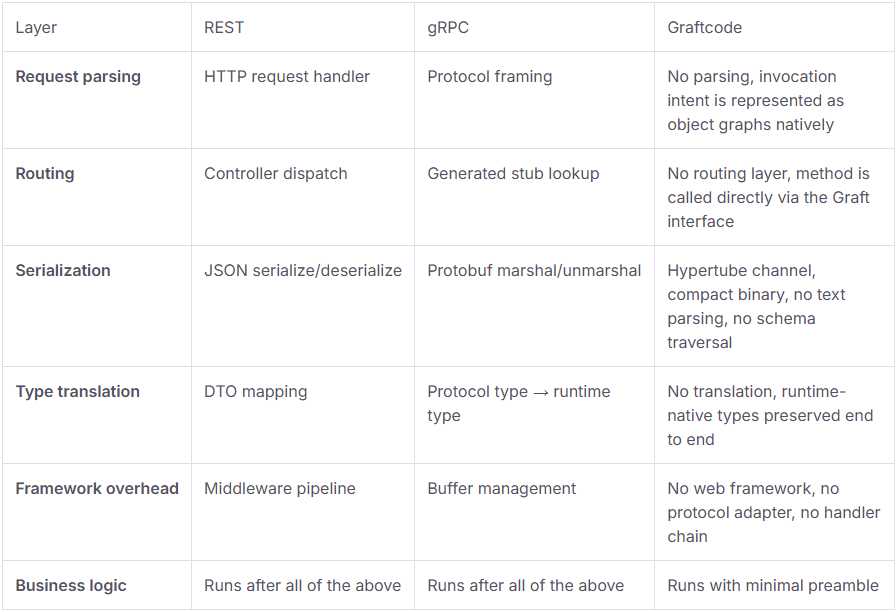
REST and gRPC both integrate above the runtime, REST at the web framework level, gRPC at the protocol level. Every call passes through this stack regardless of how simple the business logic is. Graftcode integrates at the runtime level, representing invocation intent directly as object graphs and executing using native runtime semantics. There are no controllers, no handlers, no protocol adapters. The execution path is shorter by design.
To make this concrete, here is what the full call path looks like for each protocol, from the moment the calling service makes a request to the moment business logic fires.
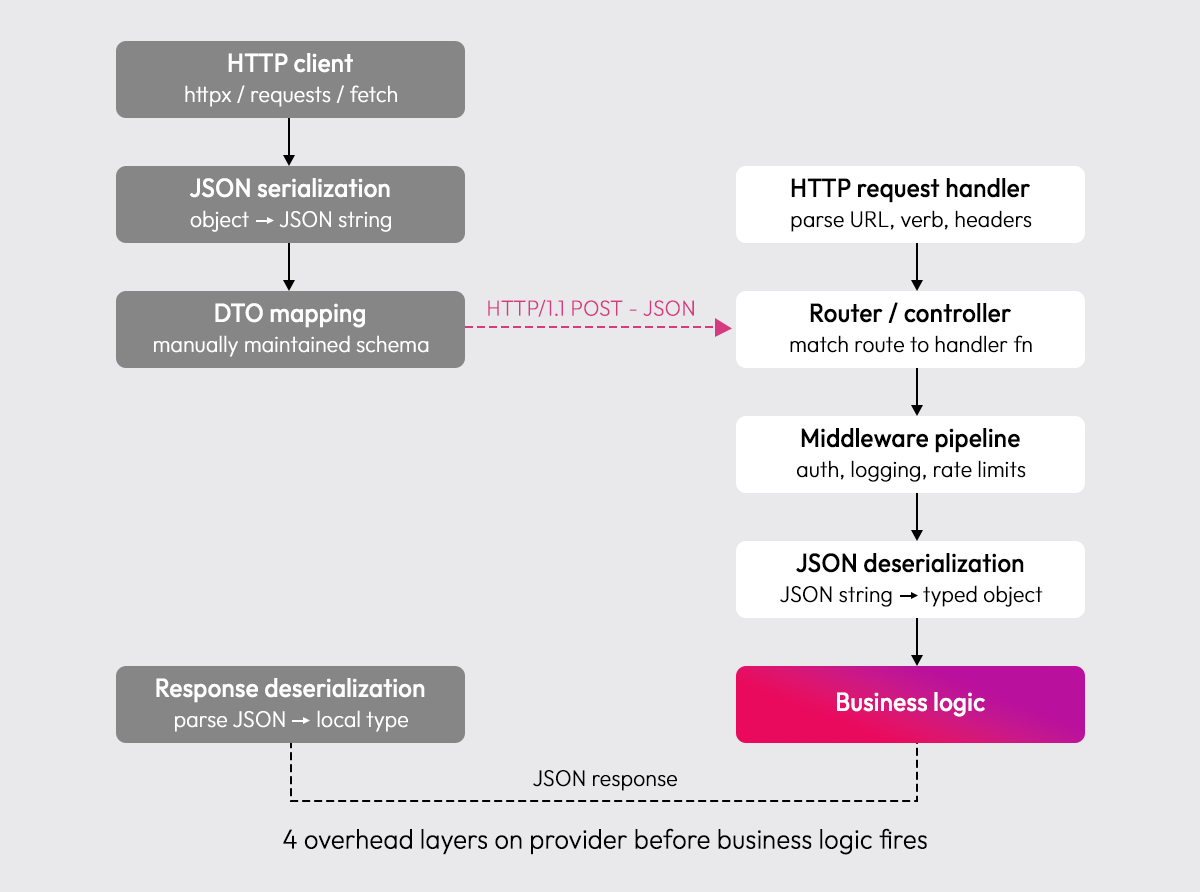
REST's overhead is visible across three layers on the calling side alone before the request even crosses the network, and four more on the provider side before logic runs.
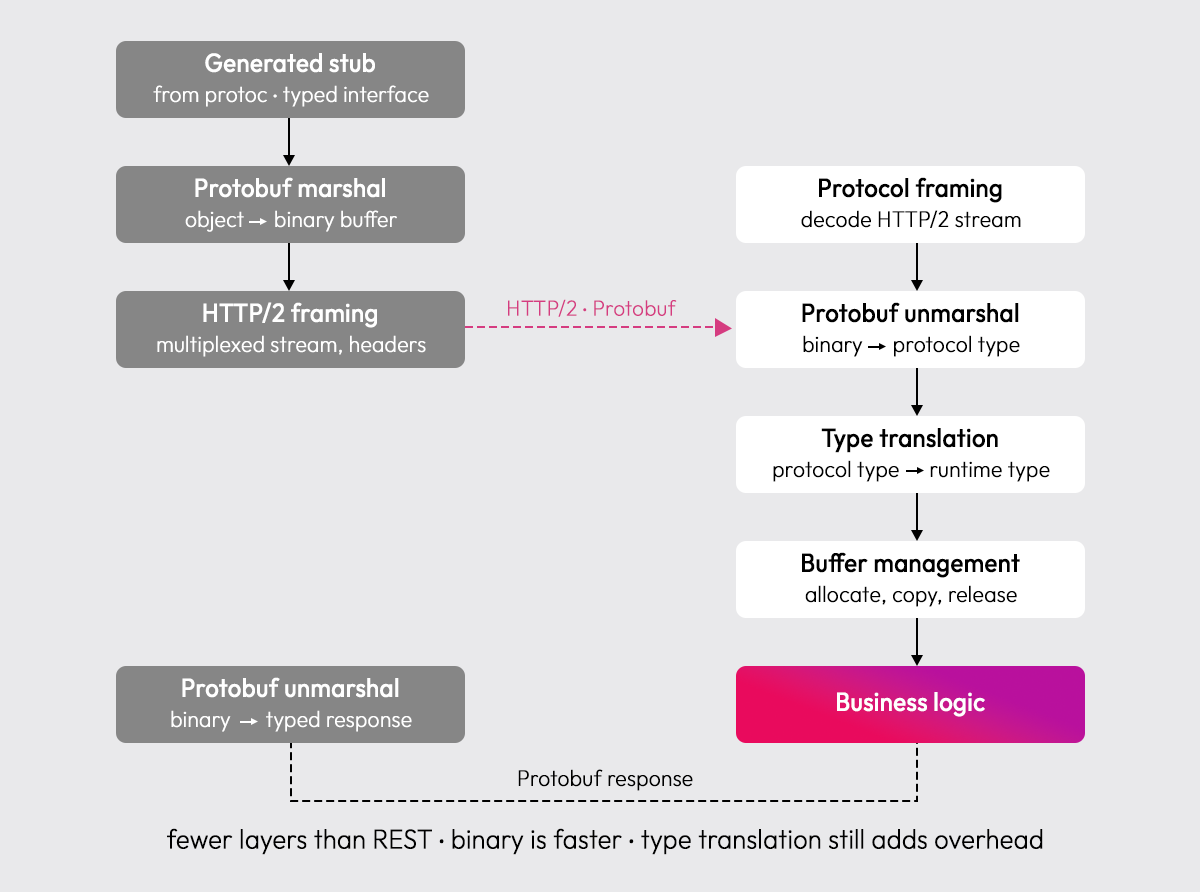
gRPC cuts the calling side to three layers and drops the middleware pipeline, but the type translation and buffer management steps on the provider side are costs REST doesn't have in the same form. Both protocols pay an integration overhead, just a different shape of it.
Serialization: JSON vs Protobuf
JSON is text, readable, flexible, and universally supported. Protobuf is binary, compact, typed, and faster to encode and decode. A typical Protobuf payload runs 3–10x smaller than its JSON equivalent. At low call volumes the difference is negligible. At high throughput, agent orchestration loops, inference pipelines, tool execution chains, it compounds fast.
Streaming in practice: token output over REST vs gRPC
Streaming is where the protocol difference becomes most visible for 2026 workloads. LLM token streaming, live agent status updates, real-time tool execution results, all of these require the server to push data incrementally as it becomes available. Here's what that looks like in practice for each protocol.
The **.proto** for a streaming inference service:
syntax = "proto3";service InferenceService {// Unary -- full response at oncerpc RunInference (InferenceRequest) returns (InferenceResponse);// Server streaming -- tokens pushed as they're generatedrpc StreamInference (InferenceRequest) returns (stream InferenceToken);}message InferenceRequest {string model = 1;string prompt = 2;int32 max_tokens = 3;}message InferenceResponse {string output = 1;int32 tokens_used = 2;}message InferenceToken {string token = 1;bool is_final = 2;}
REST: token streaming via Server-Sent Events:
SSE is the standard REST approach for server-push. It works, but it runs on a separate infrastructure path from your regular API calls, a different content type, different client handling, and no shared transport with your other endpoints.
# Server (FastAPI)from fastapi import FastAPIfrom fastapi.responses import StreamingResponseimport asyncioapp = FastAPI()async def token_generator(prompt: str):tokens = ["The", " quick", " brown", " fox", "..."]for token in tokens:yield f"data: {token}\n\n"await asyncio.sleep(0.1)yield "data: [DONE]\n\n"@app.post("/stream_inference")async def stream_inference(req: InferenceRequest):return StreamingResponse(token_generator(req.prompt),media_type="text/event-stream")
# Client -- SSE requires a separate library (httpx-sse)import httpxfrom httpx_sse import connect_ssewith httpx.Client() as client:with connect_sse(client, "POST", "http://inference-service/stream_inference",json={"model": "llama-3", "prompt": "Summarize this", "max_tokens": 512}) as event_source:for event in event_source.iter_sse():if event.data == "[DONE]":breakprint(event.data, end="", flush=True)
gRPC: native server streaming:
gRPC's server streaming runs over the same HTTP/2 connection as every other call, no separate infrastructure, no different client setup.
# Serverclass InferenceServicer(inference_pb2_grpc.InferenceServiceServicer):def StreamInference(self, request, context):tokens = ["The", " quick", " brown", " fox", "..."]for i, token in enumerate(tokens):is_final = (i == len(tokens) - 1)yield inference_pb2.InferenceToken(token=token,is_final=is_final)
# Clientstub = inference_pb2_grpc.InferenceServiceStub(channel)try:for token_response in stub.StreamInference(inference_pb2.InferenceRequest(model="llama-3",prompt="Summarize this document",max_tokens=512),timeout=60.0):print(token_response.token, end="", flush=True)if token_response.is_final:breakexcept grpc.RpcError as e:print(f"Stream interrupted: {e.code()} -- {e.details()}")
The difference in practice:
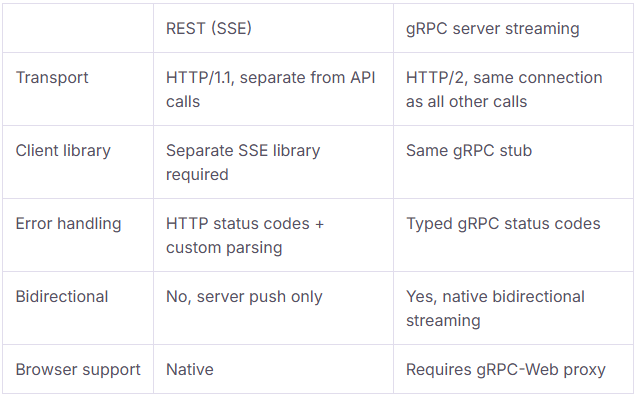
For token streaming specifically, one direction, server to client, SSE works fine. For teams where gRPC-style server streaming is the requirement, token output over a typed RPC stream, bidirectional tool calls mid-request, gRPC is the most direct fit. Graftcode approaches streaming differently: through stateful service interactions, callbacks, and duplex communication that replace WebSocket or SignalR patterns. The two models aren't equivalent, but Graftcode isn't a non-starter for event-driven or push-based patterns, it handles them through a different mechanism. Worth evaluating against your specific use case before ruling it out.
Browser and client compatibility
REST works natively in every browser and HTTP client. gRPC requires a gRPC-Web proxy layer for browser clients, the browser's fetch API doesn't support HTTP/2 trailers, which gRPC depends on. This is a hard constraint and the primary reason gRPC stays scoped to internal service-to-service communication for most teams.
[3]Why REST Is Still the Right Call for External-Facing APIs
REST's strength is breadth, it works everywhere and asks nothing of the caller. The scenarios where that matters most are fairly consistent across teams.
Public-facing APIs are the clearest fit. Any client, browser, mobile app, third-party integration, CLI tool, can call a REST API over HTTP with no stubs, no generated code, and no special setup. If the API has external consumers, REST is the default for good reason.
Rapidly evolving interfaces also favor REST. Early-stage products, exploratory internal services, APIs that change weekly, skipping the .proto maintenance cycle means faster iteration. When the schema isn't stable yet, the overhead of enforcing it is friction you don't need.
Human-readable debugging is an underrated advantage. A REST call gone wrong is inspectable in curl, Postman, or browser devtools immediately. A Protobuf payload needs a deserializer and the right .proto file to make sense of. For teams onboarding new engineers or debugging cross-service issues under pressure, that difference is felt.
REST is the right fit when:
- The API has external consumers, browsers, third parties, mobile clients
- The interface is still being shaped and changes frequently
- Broad tooling compatibility matters more than raw performance
- The team needs fast onboarding and easy debugging
One thing worth noting: REST's lack of enforced schema is manageable at small scale. As the number of services and consumers grows, the manual discipline required to prevent contract drift grows with it. Teams that start with REST often end up investing in OpenAPI specs, contract testing, and SDK generation anyway, doing manually what gRPC enforces by default.
[4]When Is gRPC the Right Call for Internal, High-Throughput Services
gRPC's overhead is front-loaded, the .proto file, the stub generation, the regeneration cycle. Where that investment pays back is in systems where call volume is high, latency matters, and you control both ends of the connection.
High-throughput internal services are the primary use case. An inference service fielding thousands of requests per minute, a tool execution pipeline inside an agent loop, a feature store queried by multiple downstream services, these workloads feel the difference between JSON over HTTP/1.1 and Protobuf over HTTP/2. Smaller payloads, persistent connections, and multiplexing compound at scale.
Polyglot service meshes benefit significantly from gRPC's code generation model. When a Python orchestrator, a Go inference service, and a Java data pipeline all need to share an interface, the .proto file generates consistent typed stubs in each language. The contract is shared and enforced across the board, no risk of one language silently misinterpreting a field another language set.
Latency-sensitive workloads are where gRPC's HTTP/2 transport has the most visible impact. The clearest 2026 example is a multi-tool agent loop, an orchestrator calling a retrieval service, a code execution service, and a summarization service per request.
With REST, each service gets its own connection pool:
async with httpx.AsyncClient() as client:retrieval = await client.post("http://retrieval-service/retrieve", json={...})execution = await client.post("http://execution-service/execute", json={...})summary = await client.post("http://summary-service/summarize", json={...})
With gRPC, all three calls run in parallel over persistent HTTP/2 channels:
with futures.ThreadPoolExecutor(max_workers=3) as executor:r = executor.submit(retrieval_stub.Retrieve, RetrieveRequest(...), timeout=10.0)e = executor.submit(execution_stub.Execute, ExecuteRequest(...), timeout=10.0)s = executor.submit(summary_stub.Summarize, SummarizeRequest(...), timeout=10.0)
At 20 tool calls per agent run, 5ms saved per hop is 100ms off the total response time. That gap compounds directly into the cost savings the Performance Lab benchmarks show.
The same dynamic applies to how AI tools reason about these systems during development. A retrieval + execution + summarization loop implemented with REST or gRPC carries significant integration surface area, HTTP clients, proto files, stub imports, DTO mappings, that an AI coding assistant has to parse and hold in context. With Graftcode, that surface area disappears from the codebase entirely. The AI context window focuses purely on business logic, which improves the accuracy and success rate of AI-generated changes, on both greenfield development and later maintenance and evolution of the system.
gRPC is the right fit when:
- Services are internal and you own both the client and the server
- Call volume is high enough that payload size and connection overhead matter
- Multiple languages need to share a strict, enforced interface contract
- Streaming patterns are part of the design, token streaming, live status updates, bidirectional flows
- An agent loop is calling multiple downstream services per request in parallel
[5]The Integration Maintenance Cost That Accumulates Regardless of Protocol
Picking a protocol solves the transport question. What it doesn't solve is the integration maintenance work that sits on top of it, and that work accumulates with every service added to the system. Writing HTTP clients, keeping DTO schemas in sync, and managing stub regeneration can consume 30–40% of backend engineering time.
What the integration code looks like with REST and gRPC
With REST, every service integration means writing and maintaining an HTTP client:
import httpxfrom pydantic import BaseModelclass InferenceRequest(BaseModel):model: strprompt: strmax_tokens: intasync def run_inference(prompt: str) -> dict:async with httpx.AsyncClient(timeout=30.0) as client:try:response = await client.post("http://inference-service/api/v1/inference",json=InferenceRequest(model="llama-3",prompt=prompt,max_tokens=512).dict())response.raise_for_status()return response.json()except httpx.HTTPStatusError as e:print(f"HTTP error {e.response.status_code}: {e.response.text}")raise
With gRPC, the stub handles transport, but the .proto maintenance cycle is now the team's responsibility:
# Every time the inference service changes its interface:protoc --python_out=. --grpc_python_out=. inference.proto# Commit the regenerated stubs# Update every calling service that imports them
And what interface drift looks like in practice:
# Provider renames max_tokens → max_new_tokens in .proto# Without regenerating stubs: silent wrong behavior# After regenerating: compile error immediately -- caught before productionstub.RunInference(InferenceRequest(model="llama-3", max_tokens=512))# ^^^^^^^^^^# TypeError: unexpected keyword
Both approaches leave the same problem: keeping the calling service in sync with the provider is manual work that scales with the number of services.
Where Graftcode fits in
Instead of writing HTTP clients or running protoc, the calling service installs a Graft via its package manager:
pip install --index-url https://grft.dev/your-project-id inference-service@1.0.0pip install --index-url https://grft.dev/your-project-id retrieval-service@1.0.0pip install --index-url https://grft.dev/your-project-id summary-service@1.0.0
The same three-service agent loop from above section becomes:
from inference_service import InferenceServicefrom retrieval_service import RetrievalServicefrom summary_service import SummaryServicedef run_agent_loop(query: str, prompt: str, text: str) -> dict:retrieval = RetrievalService.retrieve(query=query)inference = InferenceService.run_inference(model="llama-3",prompt=prompt,max_tokens=512)summary = SummaryService.summarize(text=text)return {"retrieval": retrieval,"inference": inference,"summary": summary}
One current constraint worth noting: primitive wrapper types (Date, Guid, TimeSpan) are not supported, pass them as string or int instead. Check the Alpha constraints page for the full list.
No HTTP client, no DTO, no stub regeneration. If any provider changes its interface, the update surfaces as a package update, caught at compile time. Teams control when to apply it.
For teams using AI coding assistants, the code reduction has a direct impact. Graftcode eliminates the integration layer from the codebase entirely, no HTTP clients, no DTOs, no stub files. According to Graftcode's website, this reduces token usage by 30–60% on integration-heavy services, letting the AI focus on business logic rather than protocol boilerplate.
Pull requests get cleaner too. With REST or gRPC, an interface change touches the HTTP client, the DTO, the stub, and the business logic, across multiple files. With Graftcode, the only thing that changes in a commit is the business logic. The integration layer doesn't appear in the diff because it doesn't exist in the repo.
Error handling uses native exceptions, no status code translation layer:
try:result = InferenceService.run_inference(model="llama-3", prompt=prompt, max_tokens=512)except Exception as e:# Native exception from the provider service -- same try/catch as local code# No HTTP status codes, no gRPC status mappingprint(f"Inference failed: {e}")raise
How the routing actually works
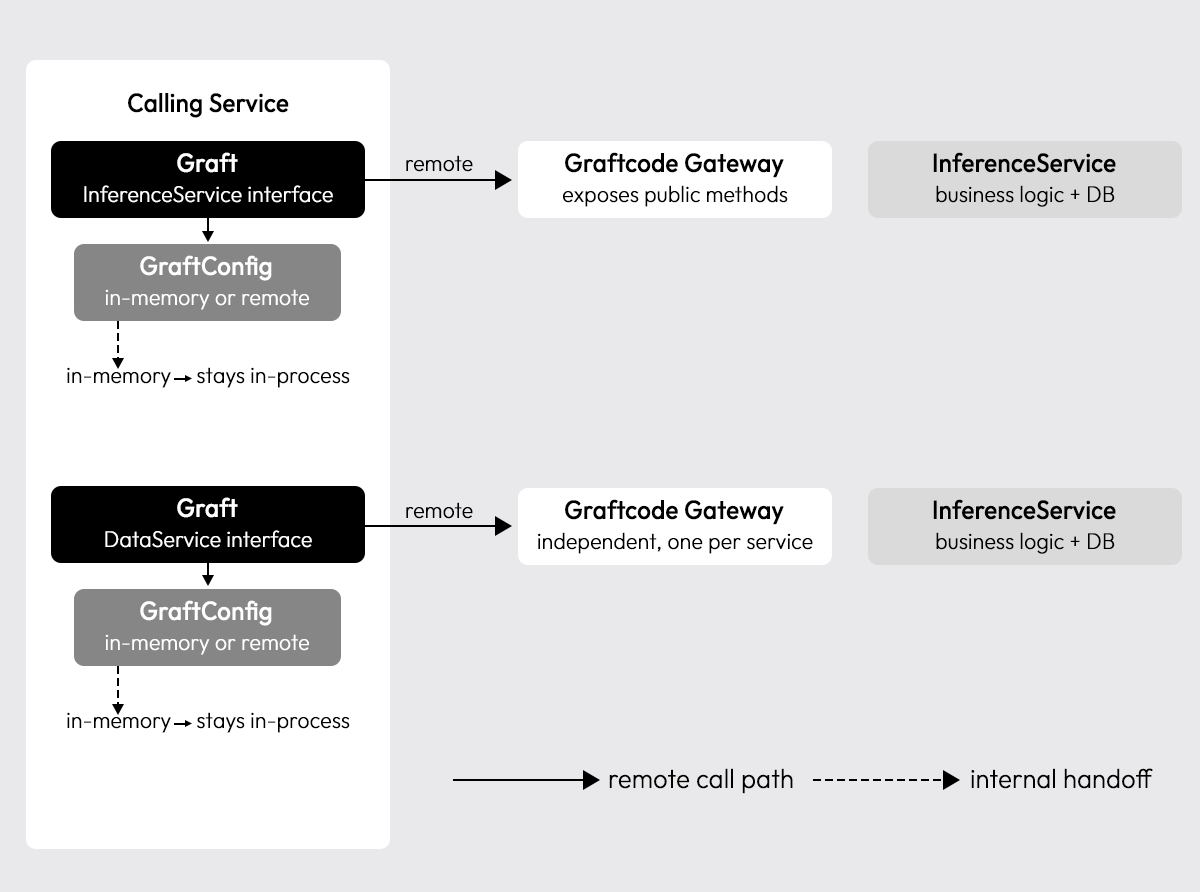
GraftConfig lives inside the calling service and controls whether the call runs in-process or hits the deployed service remotely, switched via environment variable, config file, or directly on the Graft. No code change required.
Service mesh sidecars (Istio, Linkerd) and feature flag systems can achieve a similar local/remote toggle, but they operate at the infrastructure layer, the application code still makes a network call and the sidecar intercepts it. GraftConfig operates at the runtime level: in-memory mode means the call never leaves the process at all, no network hop, no sidecar involved. The distinction matters for local development speed and for test environments where spinning up a full mesh isn't practical.
Each provider service runs its own Graftcode Gateway independently alongside it.
How overhead compounds across CPU, memory, and network
In benchmark testing, Graftcode runs up to 70% faster than traditional web services with one-eighth the CPU overhead. The Performance Lab's large-payload test, 5,000 data points per call, all three on the same .NET runtime over HTTP/2, network latency excluded, shows Graftcode at 22ms, gRPC unary at 53ms, and REST at 1,245ms. Graftcode is 98.2% faster than REST on this workload.
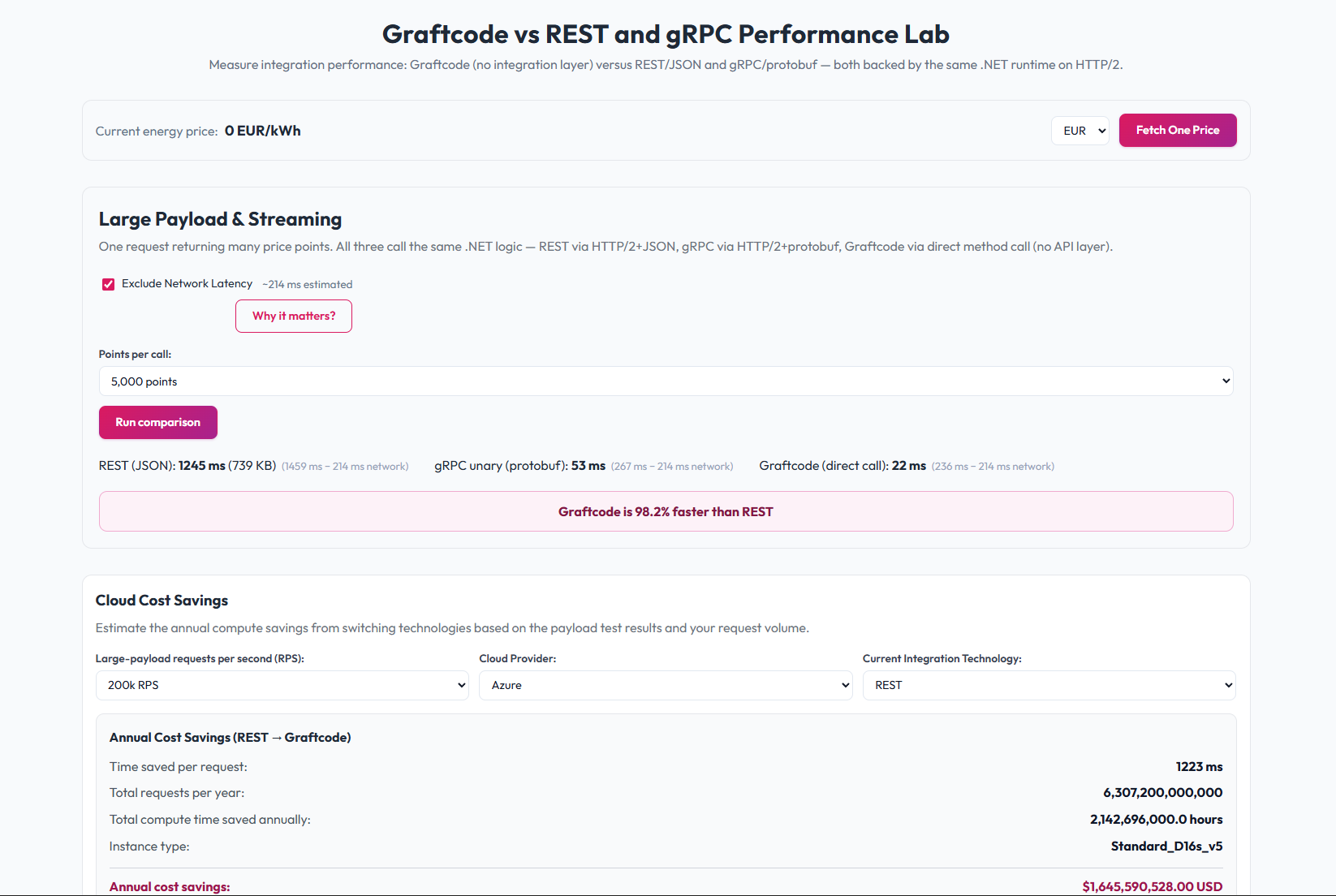
Graftcode's Performance Lab runs 1,000 calls against the same endpoint across all three, REST, gRPC, and Graftcode, with network latency excluded for a clean protocol-level comparison. It also includes a cloud cost savings calculator where you input your RPS, cloud provider, and current integration type to get estimated annual savings based on actual benchmark data.
[6]A Practical Decision Framework for Backend Teams in 2026
Protocol decisions rarely happen in isolation, they depend on who the consumers are, how much the interface will change, and what the team can realistically maintain. This table maps the signals to the right choice:
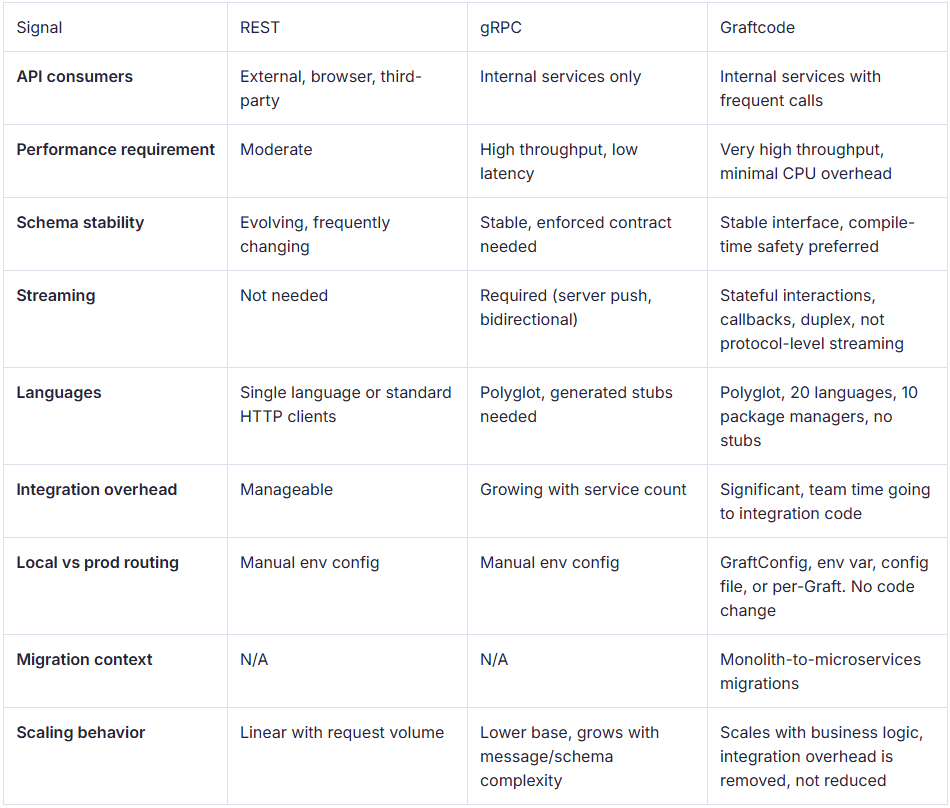
Three common scenarios
SaaS platform with a public API and third-party integrations, REST is the right call. Browsers and third-party clients need zero setup to consume it. Flexibility and tooling compatibility outweigh any performance gains from switching protocols.
ML inference service called by multiple internal services, gRPC fits well here. The interface is stable, call volume is high, latency matters, and you control both ends. The .proto maintenance cost is worth the strict contract and Protobuf performance at scale.
Microservices team with a growing number of internal services, if the team is spending meaningful sprint time on integration code, writing HTTP clients, keeping DTO schemas in sync, managing stub regeneration, the protocol choice is not the root problem. The Performance Lab benchmarks make this concrete: on a large-payload test of 5,000 data points per call, all three running on the same .NET backend over HTTP/2 with network latency excluded, Graftcode completed in 22ms, gRPC in 53ms, and REST in 1,245ms, Graftcode is 98.2% faster than REST. At 200k RPS on Azure Standard_D16s_v5, that difference translates to an estimated $1.64B in annual compute savings.
[7]Conclusion: Choosing a Protocol Is Step One of a Longer Engineering Decision
REST and gRPC solve different problems. REST is the right default for external-facing APIs where broad client compatibility matters more than raw performance. gRPC earns its setup cost in high-throughput internal systems with stable, polyglot interfaces and strict contract requirements. The decision framework above covers most cases, but the honest takeaway is that neither protocol eliminates the integration maintenance work that accumulates as services multiply.
For teams where that integration overhead is already visible, Graftcode addresses the layer both protocols leave to the team, typed interfaces generated via package manager, compile-time contract enforcement, and in-memory to remote routing via environment variable, config file, or directly on the Graft, worth exploring at graftcode.com.
[8]FAQs
1. Can gRPC and REST coexist in the same microservices architecture?
Yes, and most production systems do exactly this. External-facing APIs stay on REST for broad client compatibility while internal service-to-service communication uses gRPC for performance and contract enforcement. An API gateway at the edge handles protocol translation, REST in, gRPC internally.
2. Does gRPC support backward-compatible API versioning?
Protobuf handles backward compatibility through field numbers. Adding a new field with a new field number doesn't break existing clients, they ignore fields they don't recognise. Removing or renumbering fields does break compatibility. The standard approach is to never remove fields, only deprecate them, and introduce breaking changes via a new service version in the .proto.
3. What is the performance difference between REST and gRPC at high call volumes?
At low volumes the gap is small. At high throughput, thousands of requests per second, Protobuf's binary encoding (3–10x smaller than JSON) and HTTP/2's multiplexing produce measurable latency and CPU differences. gRPC benchmarks consistently show lower p99 latency and higher throughput than REST under load, particularly for small, frequent payloads typical of internal service calls.
4. How does Graftcode handle service discovery and load balancing compared to gRPC?
GraftConfig inside the calling service controls where the remote call goes, pointing to the Graftcode Gateway running alongside the provider service. Load balancing sits at the infrastructure layer (Kubernetes service, load balancer) in front of the Gateway, same as it would for a gRPC or REST service. Graftcode doesn't replace service mesh tooling, it replaces the integration code layer above it.
5. Is gRPC suitable for browser-based frontend applications?
Not natively. Browsers don't support HTTP/2 trailers, which gRPC requires. gRPC-Web is the workaround, it uses a proxy (typically Envoy) to translate between browser HTTP/1.1 requests and gRPC over HTTP/2. For most teams, the added infrastructure overhead makes REST the practical choice for browser-facing APIs, with gRPC scoped to internal service communication.
6. How does Graftcode eliminate integration maintenance overhead compared to REST and gRPC?
With REST, every service integration requires a hand-written HTTP client, DTO schemas, and manual synchronization when the provider changes. With gRPC, the .proto file enforces the contract but introduces a stub regeneration cycle on every interface change. Graftcode replaces both with a strongly-typed Graft installed via package manager, the integration contract is enforced at compile time, interface changes surface as package updates, and there's no HTTP client or stub file in the codebase. According to Graftcode's founder, this eliminates 30-60% of token usage for AI coding assistants on integration-heavy services, since the AI context window focuses entirely on business logic rather than protocol boilerplate.
7. Can Graftcode be used alongside existing REST or gRPC services during a microservices migration?
Yes, and this is one of the more practical use cases. GraftConfig controls whether a Graft call runs in-process or routes to a deployed remote service, switched via environment variable, config file, or directly on the Graft. During a monolith-to-microservices migration, a team can extract a service, run its Graftcode Gateway alongside it, and configure the calling code to run in-memory locally and remotely in staging and production, all without changing application code. Existing REST or gRPC services continue running unchanged; Graftcode doesn't require a full system migration and can be adopted incrementally, one service boundary at a time.
/WRITTEN BY